How Sift Trains Thousands of Models using Apache Airflow
At Sift Science, engineers train large machine learning models for thousands of customers. We need processes and tools to do this consistently and reliably. In this blog, we discuss how we use Apache Airflow to manage Sift’s scheduled model training pipeline as well as to run many ad-hoc machine learning experiments.
The Problem: Lots of tasks, lots of dependencies
At Sift, we have over 30 steps to running our model training pipeline. We have MapReduce, Apache Crunch, and Apache Spark jobs running many of our feature extraction, training, and evaluation processes. And we have a data pipeline that imports and exports data from our HBase clusters and other data sources. We have written many Java, shell, and Python scripts that handle all these steps.
It was difficult to keep track of all these processes and scripts. Our dependencies were in different places managed by different scripts and systems. Tools like cron do not even offer a way to represent dependencies between cron jobs. And when we did codify our dependencies and tasks in a dependency structure, it was not trivial to implement ways to keep track of task progress or to implement functionality to stop and restart from arbitrary points in the dependency graph.
The machine learning (ML) training pipeline quickly became too complex for our existing tooling. We needed an orchestration system that could handle any programmable task and could manage all our tasks in one place.
Summary:
- Dependencies everywhere!
- Lack of visibility into successes and failures of these tasks and the overall pipeline.
- Lack of consistency in managing all these tasks and the overall pipeline.
Airflow to the rescue!
![]()
Apache Airflow is a pipeline orchestration framework written in Python. With Airflow we can define a directed acyclic graph (DAG) that contains each task that needs to be executed and its dependencies. Airflow schedules and manages our DAGs and tasks in a distributed and scalable framework.
We did look at a couple other options in the pipeline orchestration domain: Luigi, Pinball, Azkaban, Oozie. We are not going into detail on other pipeline orchestration frameworks in this blog post. But for us, we choose Airflow because Airflow provides a central scheduler, flexibility in integrating different programmable tasks, scalable distributed design, and a healthy open source community.
With Airflow, our dependencies that spanned over Python scripts, shell scripts, Java code, and documentation… are now turned into one cohesive dependency graph that we can clearly view and manage, as well as click through, obtain logs, and retrigger!
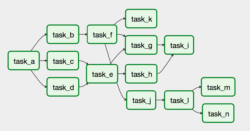
Example DAG
We now have useful time duration charts that help us find the slowest tasks in our DAG. And we also have Gantt charts that help track which tasks are slowing down our critical paths and how we might be able to parallelize different steps.

Example Time Duration Chart
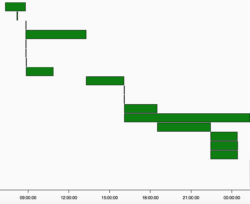
Example Gantt Chart
Additionally when problems arise, Airflow allows us to pause / unpause a DAG, as well as restart and debug our tasks one by one.
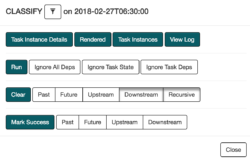
Airflow makes managing and viewing our pipeline much easier!
Airflow at Sift
In the next sections, we go over how we trigger ad-hoc ML experiment pipelines as well as general tips that we wish we had known when first integrating Airflow at Sift Science. Follow this link for the official Airflow documentation.
Triggering our DAG
We run many ad-hoc ML experiments to test new features and accuracy improvements. To achieve this in Airflow, we have to do something a little different with Airflow and its configurations.
For ad-hoc ML experiments, we need to be able to manually trigger our DAG. We also want to run our experiments in isolation. Sometimes we are testing out a new deep learning stage or modifying our DAG to implement a new optimized step. In those cases, we need to run multiple closely-related versions of a DAG.
Using a single DAG for ad-hoc experiments does not work. There might be changes to the DAG, and two engineers cannot manually trigger the DAG with their separate changes in isolation. Also, each manual run cannot be annotated in the UI with a user_id or a run_id. This makes it difficult to keep track of the many experiments we run. So we upload a separate DAG for each ad-hoc experiment that we run.
To achieve triggering DAG runs in isolation, we first copy over the DAG to its own timestamp-suffixed folder on the scheduler and workers. For example:
DAGS_HOME/my_dag_20180123_1241234/shared_dag.py
The DAG shared_dag.py dynamically looks up the DAG id from its parent folder name. The unique DAG id becomes my_dag_20180123_1241234_shared_dag. This DAG is viewed and managed as a separate DAG in the Airflow Webserver.
dag_root_path =os.path.dirname(os.path.realpath(__file__)))
dag_prefix = os.path.basename(dag_root_path)
my_unique_dag_id = dag_prefix + "_shared_dag”
We set the uniquely prefixed DAG id on the DAG definition. And we set schedule_interval=None on the DAG definition because the DAG is only manually triggered.
dag = DAG(dag_id=my_unique_dag_id, default_args=args, schedule_interval=None)
And then the DAG is manually triggered using the command below. Notice we can pass in a JSON configuration to be used in our DAG run.
airflow trigger_dag my_dag_20180123_1241234_shared_dag -c {'conf':'value'}
To summarize, for every ML experiment run, we copy over a DAG to a uniquely suffixed folder. The DAG uses a uniquely identifable DAG id and is shown in Airflow under its unique name. And finally, we trigger this DAG manually from Airflow trigger_dag command.
We also edit a few airflow.cfg settings to get this to work correctly. The following configuration changes allow us to trigger the DAG immediately after copying the DAG over to Airflow.
# the DAG must be unpaused to trigger
dags_are_paused_at_creation = False
# scheduler must be refreshed more often so that the DAG
# can be triggered immediately after copied over
min_file_process_interval = 1
With the above changes, DAGs are submitted to Airflow in isolation of one another by multiple developers and DAGs are triggered immediately for ad-hoc ML experiments.
For scheduled DAGs, our DAGs are simply triggered on the schedule_interval marked on our DAG. At Sift Science, we create our production trained models on a schedule.
Installing Airflow
Airflow can be installed through the Python pip package manager. We have set it up with Celery (a queue processing framework), because some of the UI functionality to clear tasks is only available if we set up Airflow with Celery. We also have to configure a backend database for Celery and a backend database for Airflow.
The Airflow config and setup is fairly straight forward. When setting up Airflow, the commands airflow initdb and airflow resetdb come in handy to fix blunders that may arise. We have three airflow services that we have to keep running: the webserver, the scheduler, and the worker(s).
The main design choice we have to make is how we intend to deploy our DAGs to Airflow under the configured DAGS_HOME directory. The Airflow scheduler and worker processes monitor the specified DAGS_HOME directory for the latest state of our DAGs. At Sift Science, we are using a push model where a developer deploys and copies new DAGs to the scheduler and workers. A lot of other companies use a pull model, where a processes regularly pulls the latest DAGs from a Git repo (ironically, this is usually done with a cron job).
Defining a DAG
The DAG is the center point from which we connect all our Operators. Some gotchas to note here that tripped us up:
start_dateshould be one scheduled interval before the time of the first DAG run. For example, if scheduling a weekly DAG to start today, we should set the start date to seven days ago.schedule_intervalis defined the same way as a cron schedule is defined. If we want to only manually trigger this DAG, set it toNone.
Creating Tasks
In Airflow, we define our tasks as Operators. Airflow has many built in Operators for Python, Bash, Slack integrations, Hadoop integrations and more. Airflow also has many Operators surrounding common patterns. These include TriggerDagOperator, which triggers a separate DAG, BranchPythonOperator which acts as a conditional point between two downstream branches of our DAG, or SensorOperators which poll and wait for programmatic states to change.
At Sift, we mostly use Python Operators to execute different Python scripts and libraries we have created. We have set up our Airflow workers as gateway nodes into our Hadoop / HBase / YARN cluster and we use the BashOperator to execute different Hadoop / HBase commands and to also submit jobs to our YARN cluster. Finally, we have also defined Operators to manage our EMR clusters. Because Airflow is programmatic, it is very easy to build our own Operators and customize our own integrations.
Setting up task dependencies
Defining dependencies is simple. Airflow has a directional Operator shortcuts >> and << which are equivalent to calling set_upstream dependencies and set_downstream dependencies. It also works on arrays:
[task1, task2, task3] >> task4
Concluding Remarks
We are very satisfied with Airflow. It has enabled us to consistently manage our machine learning pipelines and provided sufficient flexibility and scalability so we can grow our processes and team. However, there are a few issues we are still working through:
- When we have a lot of DAGs (100+) in Airflow, each with 30+ tasks, Airflow seems a bit slow on scheduling tasks when there are a lot of DAGs. This seems to be a known issue, and we are looking forward to seeing improvements here.
- We are also looking into better ways to deploy and sync new DAGs. It would be nice if Airflow handled the distribution of DAGs from the scheduler to all worker nodes. We are looking forward to new developments in the community on DAG distribution.
- The UI offers a lot of functionality, but it can be confusing sometimes. When we “clear” a task, it does not send a kill signal to the task, and figuring out how to “fail” a task is on a different UI page. Basic tooltips when hovering over icons would also be helpful.
All in all, Airflow has been great and the community is alive and healthy. We are grateful for the open source and how it has helped solve some of our problems. Thanks for reading!
If you would like to come join us at Sift Science, building the world’s trust platform, we are hiring!