Running ML Infrastructure on HBase
On May 7th, I presented at HBaseCon, demonstrating how Sift Science leverages HBase and its ecosystem in powering our machine learning infrastructure. In case you missed the talk, I’ll lay out the main points here.
There are three main types of events that we receive from customers on our platform: page views (also known as page activities), purchases (also known as transactions), and “labels”.
- Page views help us learn behavioral patterns — like browsing sequence — and are collected via a javascript snippet that lives on our customers’ sites. They are the most numerous events that we receive.
- Purchases refer to the monetary transactions happening on our customers’ platforms and are probably the most important events in terms of learning signals.
- Finally, “labels” in machine learning terminology refer to historical data points for which true value is known. For example, if a user is a known fraudster because a chargeback was issued on that user’s credit card, that user would be labeled a “bad” user. Conversely, a known good user receives a “normal” user label. Labels are one of the mechanisms by which our statistical models find correlations between the 1000+ features that we use to determine the potential fraudulence of a user.
If we take these event types and organize them in temporal order, we get a time series of events for a given user. Time series represent a powerful substrate on which we can derive machine learning features. For example, one can derive a class of velocity features by using a sliding window to track the frequency of events (successful transactions, changes of credit cards, etc.); at the same time, given the right schema of an HBase table that contains the raw events, a time series can be derived very efficiently via an HBase scan. This scenario suggests that building machine learning infrastructure on top of HBase can be a good fit.
Before we dive into batch training and HBase-powered online learning, I want to skim over the high level concepts behind supervised machine learning, specifically how it applies to Sift’s system. Typically, supervised machine learning centers on a cycle of training, predicting, and acting stages. During training, we use historical data — including some labeled data points — to find correlations between inputs and outputs. Inputs encompass both user-generated events and the metadata associated with them; outputs refer to scores between 0 and 100 that reflect the probability that a given user is a fraudster.
We use multiple machine learning models, each with its own unique method of modeling the data; however, their input and output signatures are all the same. Once the model is trained, we can act on new events or users that we haven’t observed yet, typically referred to as ability to generalize. We calculate predictions in real time and can send scores to customers in either synchronous or asynchronous ways. In the third stage of act, a customer decides how to interpret the predictions. While there are many ways to integrate with our system, a typical integration may look like this: automatically let the transaction through if the score is <70; automatically ban the user/transaction if the score >90; otherwise send it for further review.
We can now dive into how Sift Science trains classifiers and leverages HBase. Batch training is a process where we take all the historical data and rebuild the models from scratch. Batch training is important for cases when we introduce a new feature class, change internals of the classifier, or perform any other updates that aren’t compatible with being updated in online fashion. Due to the nature of processing a lot of data, batch training is very I/O intensive, memory intensive, and extremely CPU intensive – we’re building statistical models after all. So we do not run this process on our production systems that are serving live traffic; instead we use snapshots to move data to our experiment/batch cluster. Snapshots give us the ability to move terabytes of data while maintaining a consistent view of a particular point in time. This method is also useful in establishing clear data baseline for A/B experiments.
Once the data is in batch cluster, we kick off our training pipeline. The pipeline consists of many stages, driven by MapReduce but dependent on HBase for its source of data. For example, in the first stage, we read directly from HFiles to sample the data and select the events on which we will train the model. During feature extraction, we run HBase scans against a live table in a highly parallel way to calculate time series for users. During feature transformation, we use HBase to keep track of cardinalities of over 100M sets. Finally, when all stages are completed, we write out model parameters directly to HFiles and send them over to production again via snapshots.
One of the transformation stages is called “Sparse feature densification”. After we derive features from time series of activities, we end up with different classes of features like this:
- “device id features”
- “features that track email address characteristics”
- “features that capture physical address characteristics”
- “customer field derived features”
For some customers, we have over 1,000 total features. Many of these features will likely have many distinct values and very little repetition for each value. In other words, the feature is very sparse, which is problematic in learning a signal from such features. Another example with the same problem is a cookie id feature. An approach that we take is to remap the feature to a new, denser feature whose values are cardinalities of a set of good/bad users seen with different feature values. Note that the contents of each set could be different, but we only care about the cardinalities of these sets – – see the diagram below for illustration of the mapping.

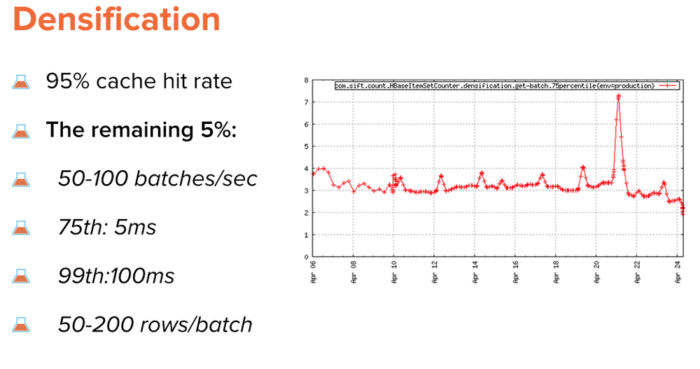
In order to support this mapping, we need to maintain cardinalities of sets of users seen with each feature value. HyperLogLog is an efficient way to do this, but it doesn’t work perfectly for us since we do need to know the exact set memberships for few more code points in the training pipeline, as well as to drive our products UI network diagram (see React Blog Post and D3 Blog Post). The system that we adopted to drive densification is a dual table HBase-backed system. The “slow” table contains all the sets (>100M set), capping each set at 8K items; the fast table stays in sync with the first table and contains just cardinalities of those sets. Most of the traffic goes against the fast cardinalities table but we do have source-of-truth sets table to consult when we need to.
The densification system is the highest traffic component of our infrastructure. It’s also an “approximately consistent” system. Under certain circumstances, we allow the cardinalities table to drift from the full set table; the drift is small and allows us to get improved latency/throughput, taking advantage of machine learning’s noise tolerance. The small amount of noise introduced via cardinalities drift is tolerated well.
To recap, in batch training we:
- Ship over the data from production;
- Run MapReduce training pipeline that interacts with HBase via direct reading/writing to HFiles and live tables; and
- Produce statistical models written out to HFiles that we ship back to production cluster via snapshots.
Due to the nature of batch training, most of the interaction is append-only, sequential read/write, and HBase has good support for such a mode of operation.
However, the previous is only half of the story of what happens with our models. Once batch trained models are deployed to production, they are constantly updated with new information streamed from our customers. This data is necessary since fraudulent patterns tend to evolve quickly and an important aspect of machine learning is that it learns new patterns. So all the same steps that run in batch mode — user time series generation, feature extraction, sparse feature densification, etc. — run in online learning mode too. Unlike batch training however, these operations are no longer append-only and/or sequential batch reads and writes; to support online learning, we really need database semantics and row-based updates. HBase’s applicability in both batch and non-batch modes is one of its strong propositions.
In summary, here is why we think HBase is a good fit for building machine learning infrastructure:
- It supports batch mode operations via HFile interactions and scans; at the same time, it supports point updates with row-based access.
- In building statistical models, there is a lot of counting; having atomic distributed increment allows us to maintain a consistent state of model parameters while supporting high read/write traffic.
- We have certain smaller tables that are mostly pinned to block cache, which translates to lower latencies.
- Snapshots allow us to move large amounts of data in a consistent state.
- Finally, much of the infrastructure described here is also used to power our API and front-end systems.
We’ve invested over two years in our HBase systems and infrastructure ensuring high-availabity and low-latency, all while growing week over week with more customers and data. We also performed a live migration between incompatible HBase versions — stay tuned for a blog post on that. While building these systems we have learned a few different lessons:
- When there is tolerance of delaying visibility, updates can be coalesced. For example, two numeric increments on the same row can be reduced to just one whose increment value is the sum of the original increments. Our coalescer delays writes by just 1 second but that’s enough to significantly reduce network traffic.
- Consistent store, such as HBase, can be used to support approximately consistent design, greatly improving latency/throughput characteristics.
- Careful schema design that avoids hot regions with appropriate hashing, salting, and pre-splitting can yield significantly improved performance.
Overall, HBase gives us both flexibility in designing our system and the ability to scale with increasing volume of requests and data.