Preloading your Javascript Split Files
By now, you’re probably familiar with the benefits of splitting up your app’s javascript into several smaller files through code splitting as opposed to serving a single behemoth. These days, code splitting is no longer even just a Webpack thing. For the Sift Science Console, we take it one step further by preloading our initial javascript split file, parallelizing its request with the entry file.
Faster First Meaningful Paints with Code Splitting
Below is an annotated network trace of how our console loads the Lists Section at console.siftscience.com/lists without preloading the initial split file. You can see how our entry file console.js loads in its entirety and, using the webpack runtime, dynamically requests the page-specific lists.js chunk. Yes, we have to request two separate javascript files for our app to be fully interactive, but we aren’t requesting, for example, account.js from the Account Section, or developer.js from the Developer Section, etc. This is a great performance win!
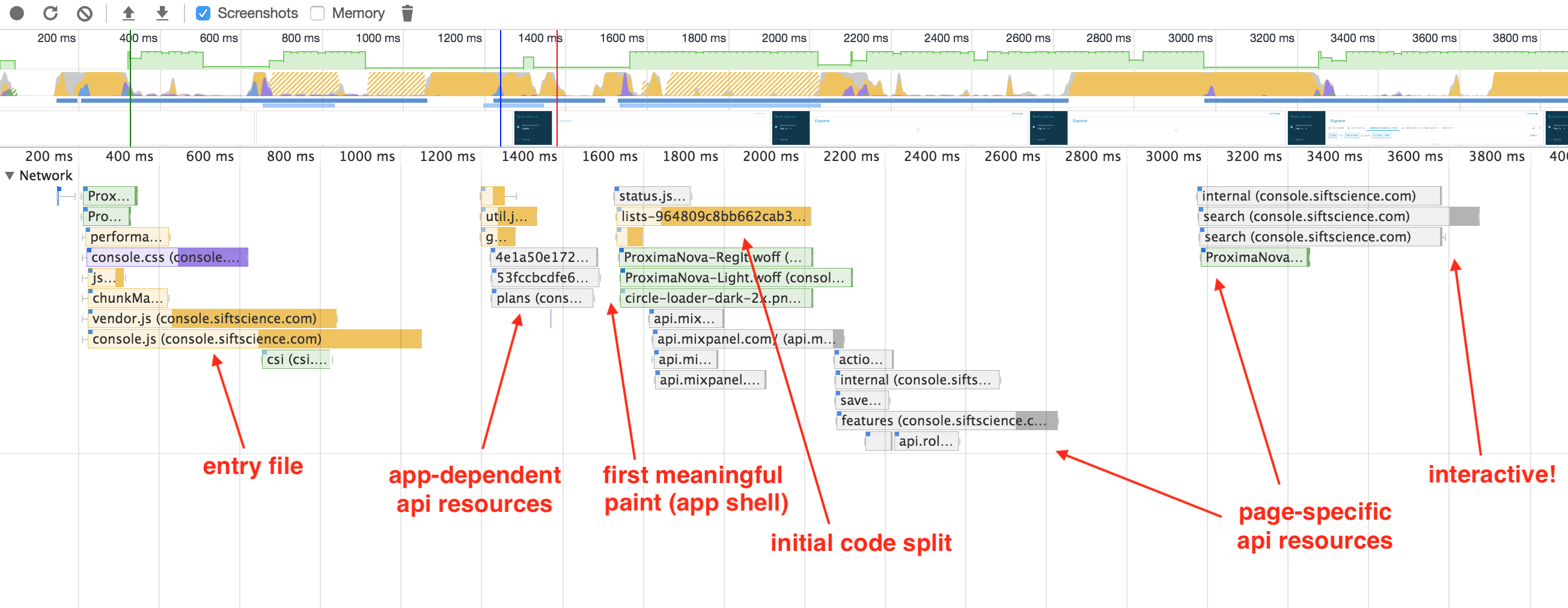
But we can do even better. Notice in this diagram that the initial code split is synchronously sandwiched between our app-dependent api resources, which are required before our console application shell can render, and the page-specific api resources, which are not known until the split file is executed. We’re waiting until the console.js entry file is fully loaded and executed before we make our page-specific javascript chunk request. But if you think about it, the only thing we need to know in order to request the split file is the URL—which is the very first piece of information we have!
So, in the spirit of the fancy new preloading spec, what if we preloaded our initial split file, parallelizing its request with the console.js entry file instead of waiting for it to load completely? That’s another 500ms we could shave off of our Time To Interactive!
Preloading the Initial Javascript Split
Okay, well we can’t use a <link rel=preload /> to preload our split file because our console is a single-page app and split files are requested dynamically based on our url route. But we can create an additional static, top-level script that has one responsibility—turning window.location.pathname into a request for the appropriate chunk. This top-level file would then be tiny (much smaller than our ~180kB entry file), and would get executed long before console.js returns, requesting the appropriate split file in parallel. When the chunk returns, it will get put into the memory cache, so that when console.js requests it as normal, it will be there waiting!
Our splitPreload.js file will look roughly like this (YMMV, depending on your own routing library and code splitting tool):
// splitPreload.js
// PageConstants maps information about what page we're on to the split it belongs to
import PageConstants from 'js/constants/page_constants';
// We refactored our routes from our router, and connected them to a PageConstant
import {Routes} from 'js/constants/route_constants';
// Within this file we have our require.ensure() methods (we still use require.ensure
// so that we can pass arrays of files), one for each split
import Splits from 'js/core/splits';
// Simply cycle through our routes and when one matches the url, find the page.
// From the page, get the split.
// Use Array.prototype.some so that once we get a match, we stop iterating.
Object.keys(Routes).some((route) => {
if (routeToRegExp(Routes[route].pattern).test(window.location.pathname.slice(1))) {
let {split} = PageConstants[Routes[route].page] || {};
// normally the split function takes a callback to render the page. but here we
// just want the chunk to get put in the cache!
split && typeof Splits[split] === 'function' && Splits[split]();
return true;
}
return false;
});
// We use Backbone's Router, so this function's contents were literally copied to turn
// our route strings into regex's for URL pathname-matching
function routeToRegExp(route='') {
// ...
}
Then, we just add this top-level file to our static index.html (either above console.js or with the async attribute):
// index.html <body> <!-- ... --> <script src="/js/splitPreload.js" async></script> <script src="/js/vendor.js"></script> <script src="/js/console.js"></script> </body>
Results
Here’s our new loading timeline:
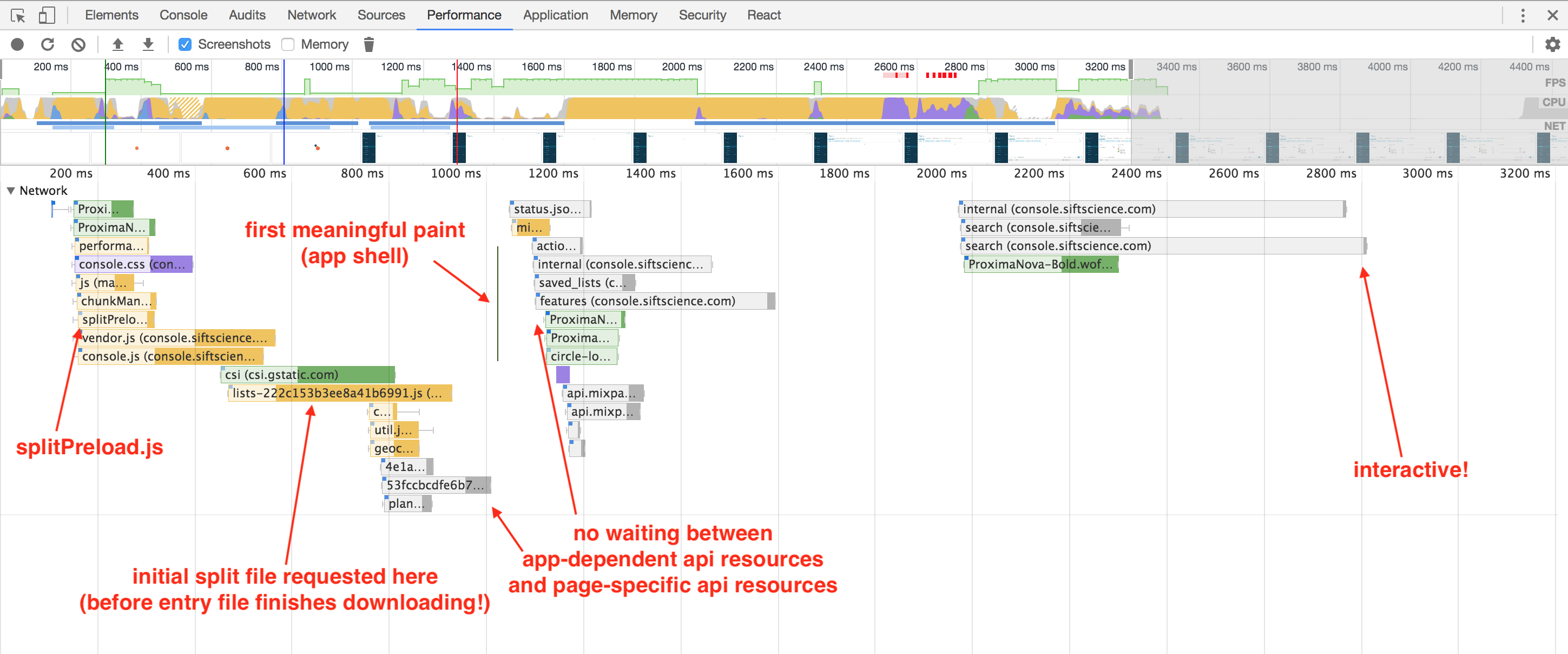
This lists.js chunk is now requested much earlier in the network waterfall, and we no longer have a synchronous request for it in between our api request blocks!
There are some small caveats here, though:
- The Sift Science Console, while we want it to be fast, is not used on mobile, where people have to pay for the data they use. Like any preloaded resource, you’ll want to be judicious about what assets you force your users to download. If, say, you had a mobile web app with a route that is likely to redirect to a route belonging to a different split file, you may want to consider blacklisting that route from the preloader.
- If your server (or load balancer) happens to still be on HTTP/1.1, you’ll also want to ensure that the extra top-level
splitPreload.jsfile isn’t blocking another server request, or if it is, that it’s a tradeoff worth making. - You can also imagine a world (perhaps soon?) where you could keep your
Routeshash on your server (especially if you render server-side), and you use HTTP2 push to send over the split file. Then we wouldn’t need to wait forsplitPreload.jsto return and execute!
In any case, code splitting has been a huge boost for web app loading performance, but preloading the initial javascript split file really takes it to the next level.
Love finding ways to cut down front-end load times? We love you. Come fight fraud with us!