How we rebuilt our app on React and Dropwizard, Part 1
By Gary Lee and Micah Wylde
Two years ago, we publicly launched our first fraud product with the goal of making it easy for anybody to leverage the same machine learning technology that protects the largest internet retailers. That product had a very simple interface: we provided one API for sending data about user behavior and another to query the fraud score of a user. But as our customer base grew, we needed better internal tools to debug and surface customer issues. A couple of engineers wrote a small Rails app, which became the first version of the Sift Science console:
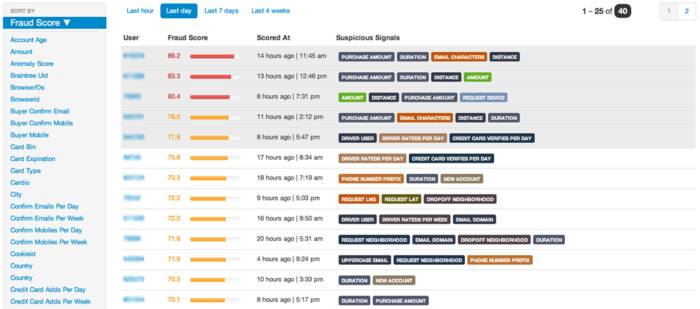
It consisted of a few pages that queried MongoDB—then our primary data store—while performing some basic filtering and formatting. The entire console was built with server-side templates and used Rails for authentication and routing.
In the summer of 2013 big changes were underway. We had a hunch that fraud analysts and e-commerce store owners would find the console to be a valuable tool, so two interns set out to build the first public-facing Sift console. Since we wanted to move quickly, we kept our APIs in Rails, which now served a single-page Backbone app. The front-end stack was rounded out with Marionette for views and Handlebars for templating. The upgraded Console launched in August 2013 and looked like this:
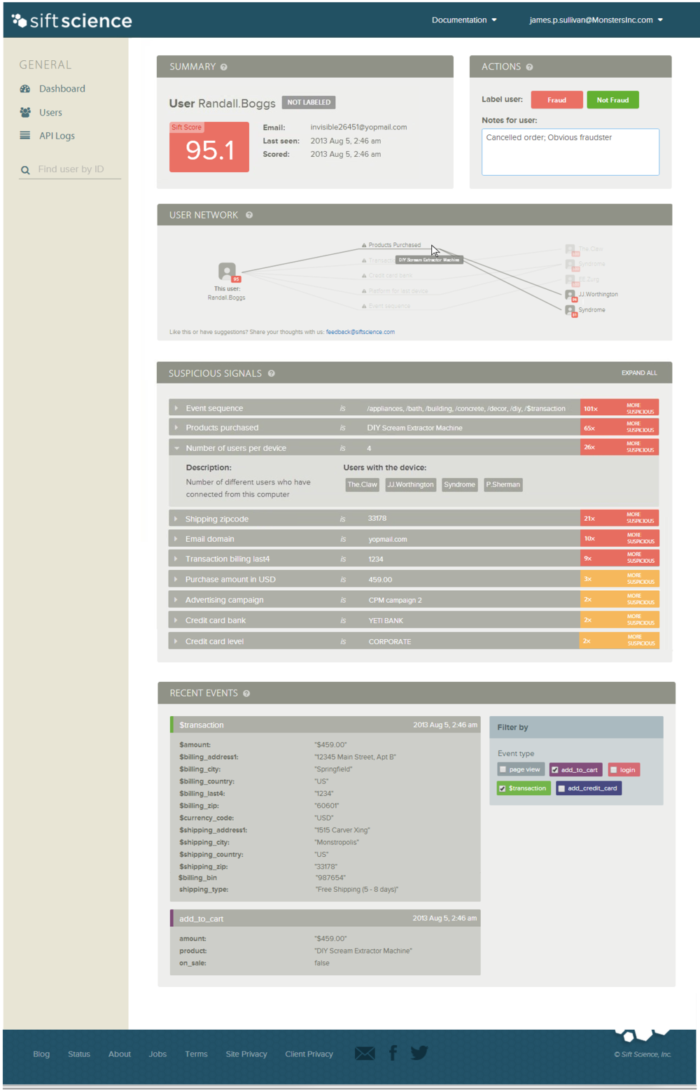
Over the next year the Console became the primary interface for many of our users and grew in features and ambition. Unfortunately, our architecture strained to keep up. We found Marionette’s two-way data binding to be unwieldy; it became difficult to share views without side-effects. We were also limited by the operators in Handlebars’ templating language, and we quickly found ourselves with a thousand-line “handlebars.helpers.js” file to manage our display logic. Our module structure grew inconsistent. Initially, our models and views were grouped together by purpose; however, as soon as we started to reuse models and views independently, we ended up needing big refactoring jobs to minimize clumsy exports and confusingly nested classes.
We realized that building reusable components would be critical for us to continue moving fast as the team and product grew. After experimenting with React, we came to a consensus that its one-way data flow and simple, declarative markup could solve a lot of our problems.
We were also hitting issues with our backend. Scaling challenges with Mongo prompted us to migrate most of our data to HBase, but there was no Ruby client at the time. Providing data to the console required three steps: 1) javascript code would 2) call a Rails API, which would 3) hit a private Java endpoint that read from HBase. In many cases, this involved replicating object representation and data manipulation code across three languages. In the best case, Rails acted as a proxy between the browser and our internal RPCs; in the worst it was adding significant complexity of its own. Taken together, it looked like this:
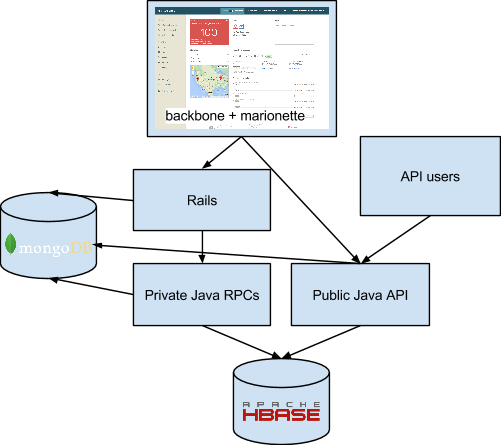
Aside from the complexity that this added to development and operation, it also limited customer and internal access to valuable data. The APIs exposed in Rails were ad-hoc, added as needed to drive the UI without much thought for reusability or design, and not suitable for others to use.
So we decided to start fresh. Our goals were three-fold: 1) simplifying development; 2) improving user experience; and 3) providing our customers greater access to their data. We began with a commitment to an API-driven development process. All new features in our console would start as APIs that exposed the necessary data. These APIs would support the console, but would also be available for internal and eventually customer use. All APIs would need a consistent, considered design and documentation. The console itself would be a consumer of these APIs, but not a special one. Built as a true client-side app, with static HTML, JavaScript, and CSS, it would have no special privileges in our system. In principle, our customers could build their own console as powerful as the one we provided.
We were also going to need new tools to make this system work. On the server side we decided to consolidate on the JVM, the platform that our machine learning and data processing code ran on, and it provided the best access to HBase. For RESTful API development, we settled on DropWizard, a collection of light-weight Java libraries for building web services.
Taken together, our new architecture looks something like this:
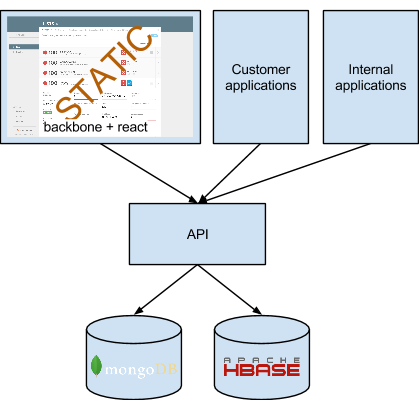
We’ll be discussing here over the next few weeks how we got from the first diagram to the second, a process that took nearly nine months. We managed the change with little customer impact, while continuing to launch features and a complete redesign.